
本書で解説されているロジスティック回帰を用いた仮想通貨価格の予測事例を参考に、USDJPY価格過去60分のdataから、5分後のUSDJPY価格を予測モデルを作成するcodeを作成した。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# Importing training data
df = pd.read_csv("USDJPY_M5_202301020700_202301192355.csv", delimiter="\t").dropna()
df = df.iloc[:,:-2]
df.columns = ["date","time","open","high","low","close","volume"]
df['percent'] = df['close'].pct_change()
df = df.dropna()
# Training data preparation
close1 = df['percent']
close2 = df['percent'].shift(-1)
close3 = df['percent'].shift(-2)
close4 = df['percent'].shift(-3)
close5 = df['percent'].shift(-4)
close6 = df['percent'].shift(-5)
close7 = df['percent'].shift(-6)
close8 = df['percent'].shift(-7)
close9 = df['percent'].shift(-8)
close10 = df['percent'].shift(-9)
close11 = df['percent'].shift(-10)
close12 = df['percent'].shift(-11)
y = df['percent'].shift(-12).apply(lambda x : 0 if x <= 0 else 1)
data = pd.DataFrame([close1,close2,close3,close4,close4,close6,close7,
close8,close9,close10,close11,close12,y]).T
data.columns = ['60mins_ago','55mins_ago','50mins_ago','45mins_ago','40mins_ago','35mins_ago','30mins_ago',
'25mins_ago','20mins_ago','15mins_ago','10mins_ago','5mins_ago','result']
data.dropna(inplace=True)
data['result'] = data['result'].astype('category')
data.tail()
X_train, x_test, Y_train, y_test = train_test_split(data[['60mins_ago','55mins_ago','50mins_ago','45mins_ago','40mins_ago','35mins_ago',
'30mins_ago','25mins_ago','20mins_ago','15mins_ago','10mins_ago','5mins_ago']],
data['result'],
test_size = 0.3,
shuffle = False
)
# Making model
lr = LogisticRegression()
lr.fit(X_train.dropna(),Y_train.dropna())
# Validation
Y_pred = lr.predict(x_test)
print('result', Y_pred)
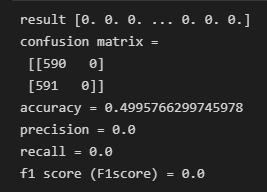
print('confusion matrix = \n', confusion_matrix(y_true=y_test,y_pred=Y_pred))
print('accuracy =', accuracy_score(y_true=y_test,y_pred=Y_pred))
print('precision =', precision_score(y_true=y_test,y_pred=Y_pred))
print('recall =', recall_score(y_true=y_test,y_pred=Y_pred))
print('f1 score (F1score) =', f1_score(y_true=y_test,y_pred=Y_pred))精度は50%であるから、予測の意味は基本的にはないということになる。
データ整形、LightGBMアルゴリズムの適用、テクニカル指標やSNSの感情、長期時間足のトレンドなどを工夫することで、予測精度を上げることが可能なようだ。